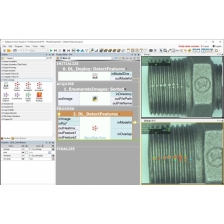

專為快速導入工業機器視覺場域應用的深度學習套件
產品簡介
當然,在工業檢測的應用場景中,如果單方面只靠傳統機器視覺演算法、或只靠深度學習,往往無法完全解決問題滿足客戶需要,因為問題本身很可能是綜合性的;Aurora Vision 本身就是一套強大的傳統視覺開發套件,所以,為了讓您能建構出更完整、更彈性的機器視覺系統解決方案,如今推出了 Deep Learning Add-on 功能,能完全支援既有的 Aurora Vision Studio 圖控操作開發環境、Aurora Vision Library 函式庫,讓您輕鬆將傳統機器視覺和深度學習整合在一起。
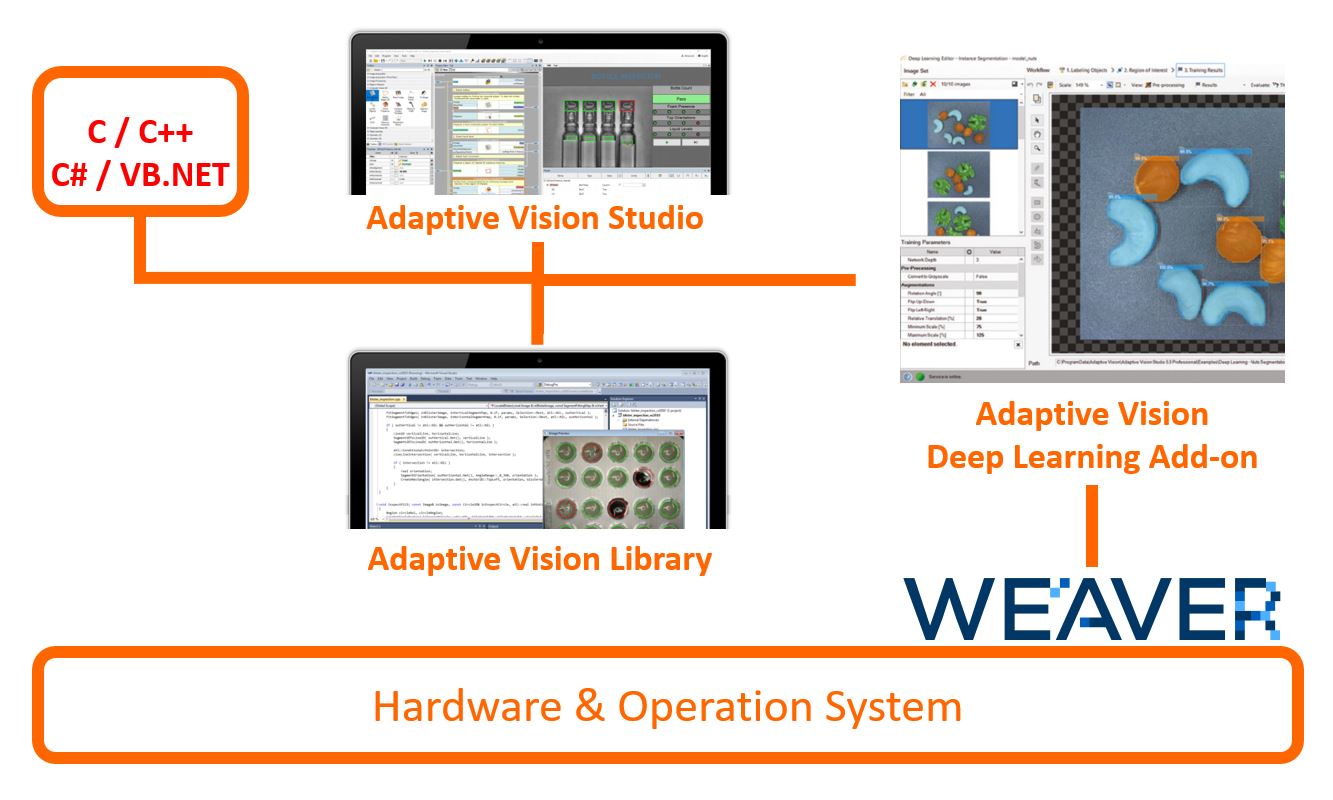
以上是 Deep Learning Add-on 的架構簡圖,除了上述提到的五大類模型以外,它還包含訓練模型的訓練資料標註圖型操作介面 (Labeling GUI)、模型訓練引擎 (Training Engine)、以及辨識時執行速度飛快 WEAVER 推論引擎 (Inference Engine) 等等,全都已經準備妥當,您身為一個開發機器視覺檢測應用的工程師只要呼叫它,不需要因為專案必須用到深度學習解決問題,而花時間去研究深度學習模型如何創建、GPU 加速如何取用、模型及訓練資料檔如何管理、資料標註 (Labeling) 程式設計、影像資料擴展 (Image Augmentation) 等等瑣碎的細節,它都已經幫您搞定了,大大節省開發時程。 無論您是用 Aurora Vision Studio 還是 Aurora Vision Library,都能直接取用 Deep Learning Add-on 資源;因此,如果您習慣於圖控式流程圖環境來開發,您可以用 Aurora Vision Studio 來呼叫深度學習,如果您習慣撰寫程式碼,您也可以用 Aurora Vision Library 來呼叫深度學習;然後它的影像資料結構都是相容的,方便您串接、排列組合各種流程。
為何選擇 Deep Learning Add-on ?
針對工業檢測應用
Segmentation、Point Location、OCR,均為針對工業應用所設計優化,只要約 20 ~ 50 張影像做訓練,一般即可達到應用需要。
支援 GPU / CPU
最佳性能
操作簡易 / 開發迅捷
只要少量樣本就能學習
最佳整合性 / Total Solution
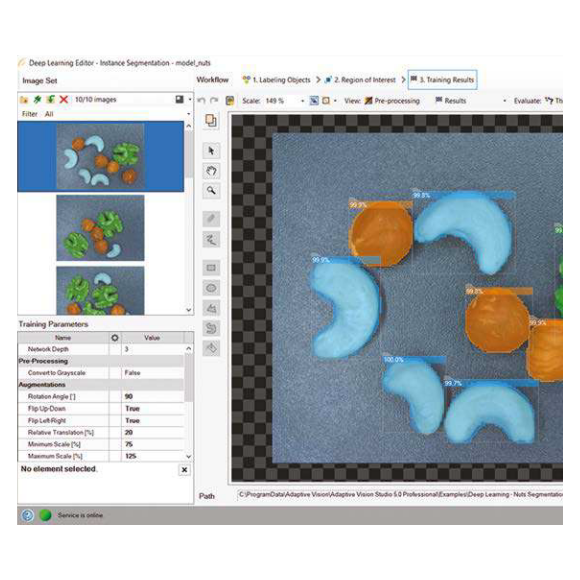
簡單的示範訓練流程
以 Object Classification 模型為例
1.收集影像並保持均一化
- 取得 20 ~ 50 張影像,好壞都要,影像要盡可能涵蓋物件的變化。
- 均一化: 每張影像中物件的比例、方向和明暗盡可能保持一致。
- 為了最佳化訓練成功率與效率,我們策略上把模型的學習重點放在區分良品或瑕疵。
- 如果可以的話盡可能避免讓它多分心於學習物件比例、方向、明暗度的變化。
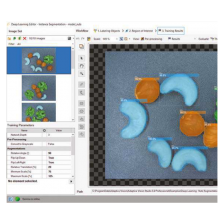
- 打開 Adaptive Vision Studio 並選擇 Deep Learning 的 Object Classification 工具。
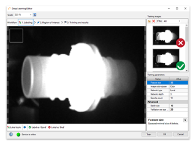
- 打開工具中的編輯器,並載入影像
- 開始標註影像或使用繪圖工具做記號 (您也可以從 Zillin 雲端空間匯入資料)
- 點擊 “訓練”
|
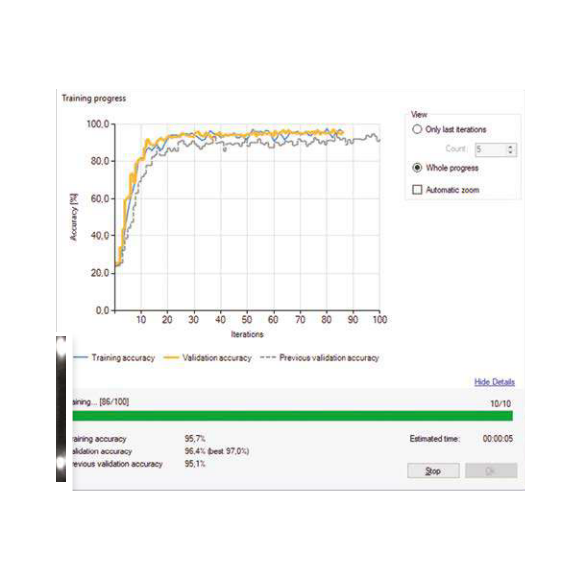
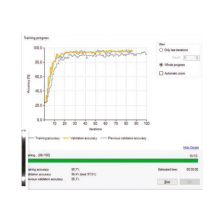
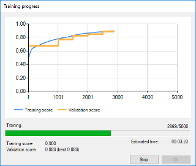
訓練資料集和驗證資料集
使用深度學習如同在機器學習的各個領域一樣,遵循正規手法是非常重要的,尤其是將訓練資料集和驗證資料集分開。訓練資料集是用於訓練模型的一組樣本,我們不能用它來衡量模型的性能,因為這容易產生過於樂觀的結果。因此,我們應該故意用另外一組的樣本 (驗證資料集) 來評估模型。我們的深度學習工具會根據用戶匯入的樣本,在學習過程中會自動分配樣本進行交叉驗證。 |
3.執行模型推論
- 執行主程式,並查看結果
- 您可以另外準備一組測試資料集,完全不匯入訓練工具,只在推論的時候測試看看模型是否真的達到您想要的泛用性
- 重複步驟 1、2 直到結果完全令人滿意。

FAQ 常見問題
Aurora Vision 深度學習套件與 TensorFlow 或 PyTorch 有什麼不同 ?
既然我可以選擇用開源神經網絡框架,為何還是該使用 Aurora Vision 深度學習套件?
此外,我們有專業的技術團隊進行技術支援,我們的深度學習套件經過多年開發、測試和微調,讓您立即將其應用到您專案項目中。我們有完整的解決方案,深度學習不是孤軍奮戰,而是配合Aurora Vision Studio偕同開發的艦隊,在衡量成本效益的同時,性價比遠高於用開源框架從頭到腳用的去建構整套解決方案。
如果我已經熟悉用開源神經網絡框架做模型了呢?
有哪些顯示卡有支援?
由於 Aurora Vision Deep Learning 軟體版本會不斷推陳出新,顯示卡的型號也一直在世代交替,我們提供網頁來查詢最新版的軟體是否對應顯示卡核心的版本。
查詢方法如下:
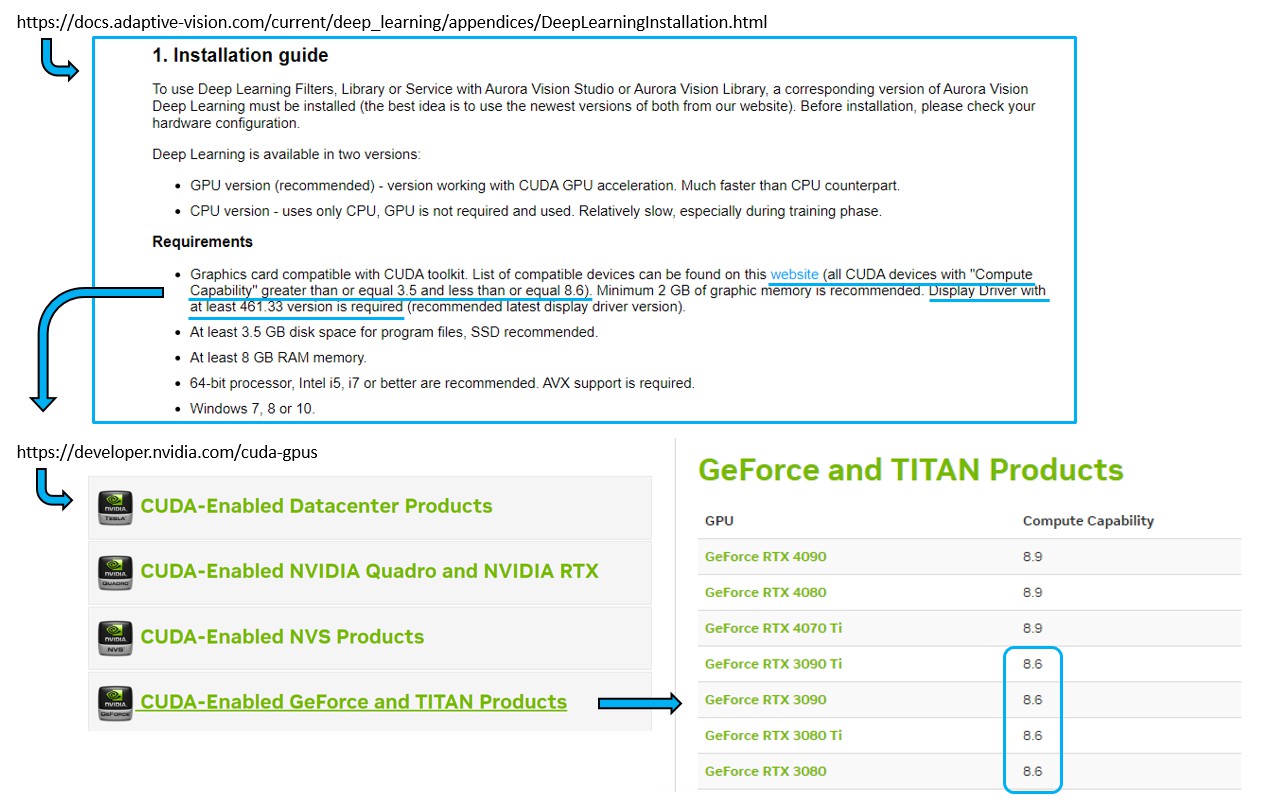
- 先造訪 Aurora Vision Deep Learning 安裝說明網頁
- 會列出最新版本支援到多少的【CUDA Compute Capability】版本區間,例如當下截圖顯示 >= 3.5、<= 8.6,以及顯示卡驅動程式版本至少要 461.33 以上;總共兩項資訊
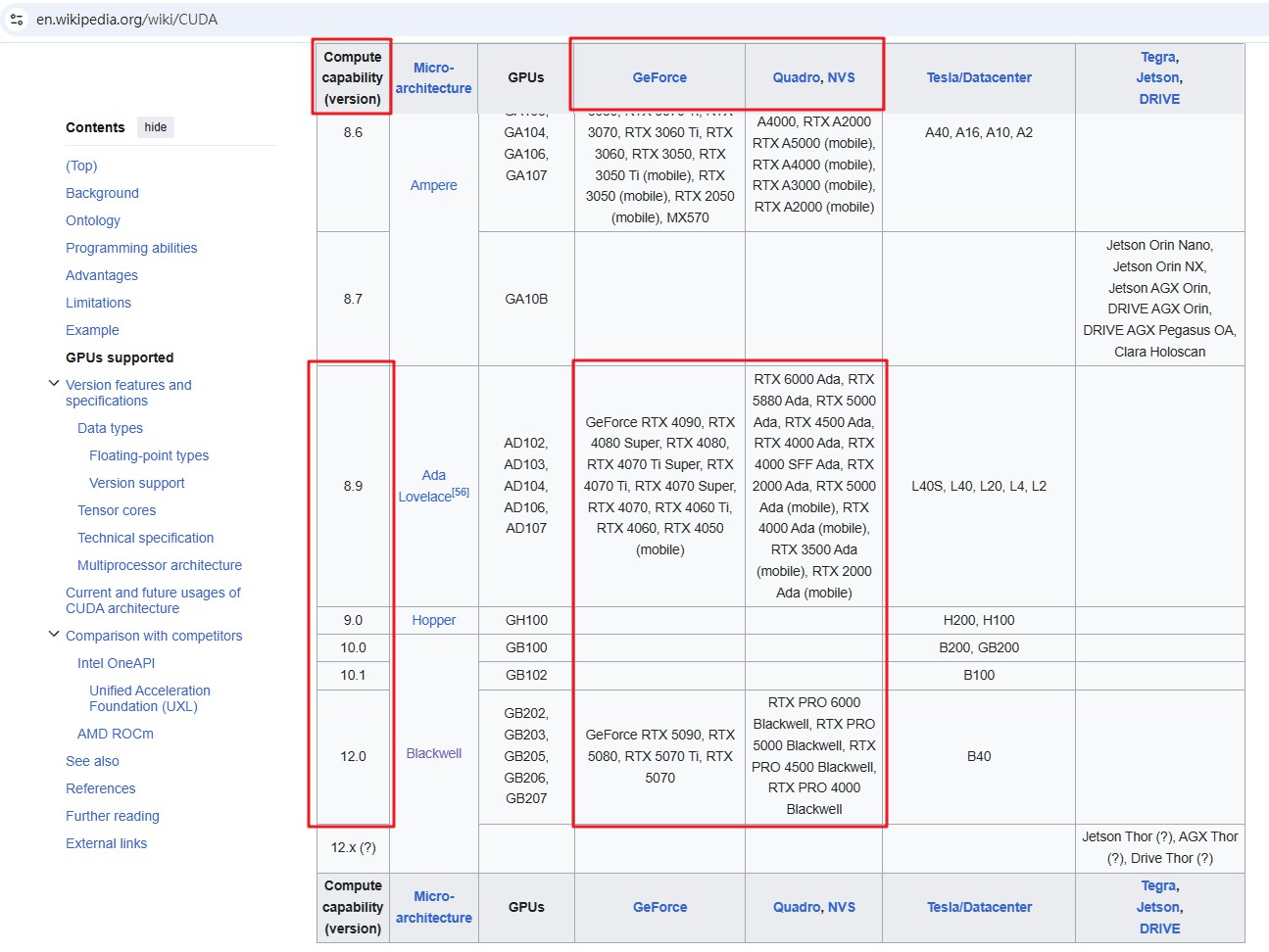
- 點擊 Website 超連結會跳轉到 nVidia GPU 官網列表 或 維基百科
- 從列表中找到您的顯示卡屬於哪一個產品線以及核心型號,例如 Gefore 系列,接下來找到該型號的 Compute Capability 數值是否落於上述 2. 查到的區間內,若有在區間內表示該款核心的顯示卡有已經在當下最新版的 Aurora Vision Deep Learning 支援範圍內。
如果沒有顯示卡怎麼辦?
- 我們有支援 CPU 計算
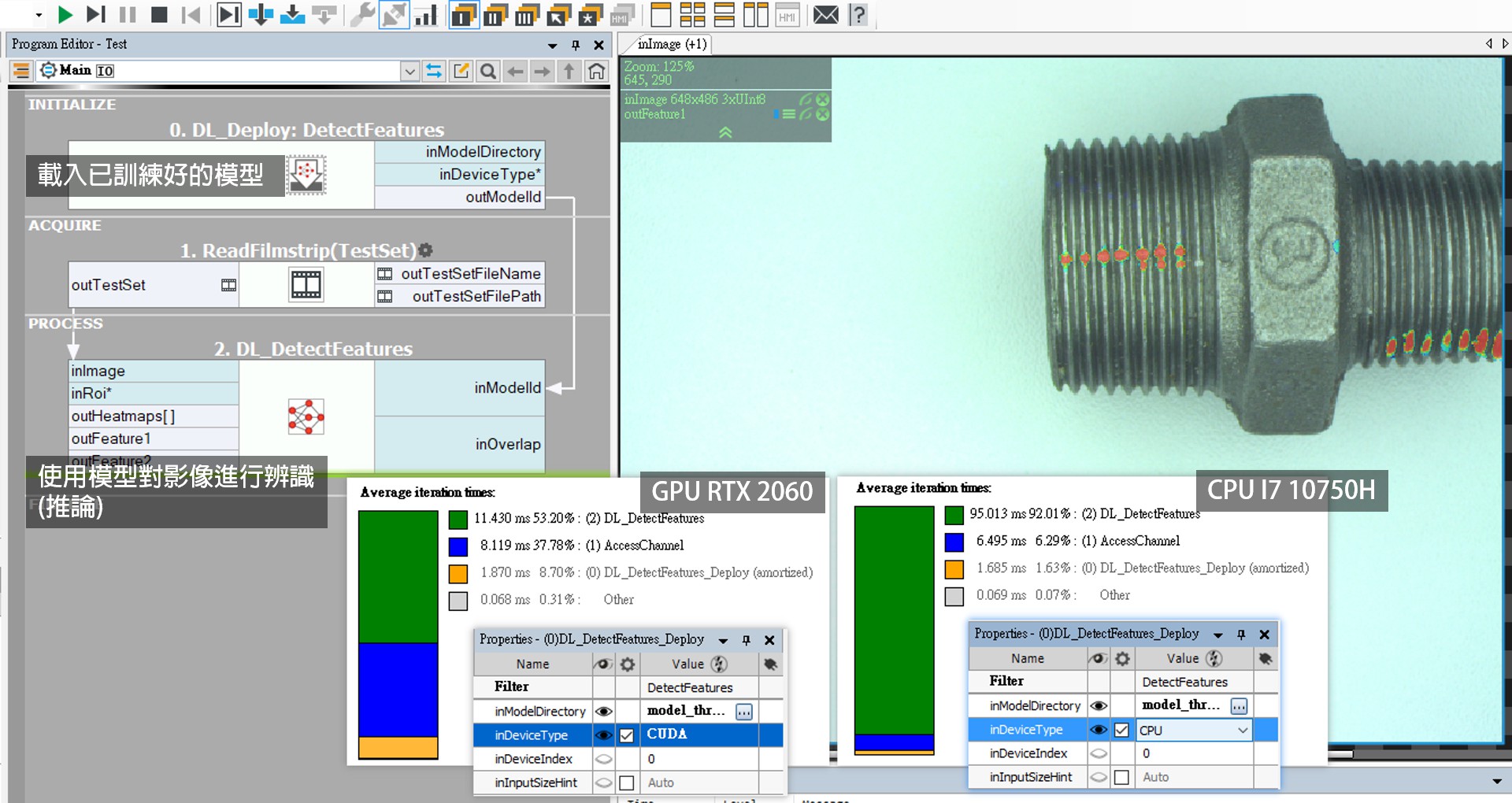
- 還是建議用有 GPU 的電腦進行訓練: GPU 執行深度學習的速度比 CPU 快很多。尤其是【訓練模型】的時候,GPU 可能只要 10 分鐘,但用 CPU 可能要數個小時,所以不建議使用 CPU 來進行訓練。所以用有 GPU 的電腦先把模型訓練好,再移植到無 GPU 的電腦上是一個選擇。
- 在沒有 GPU 的電腦用 CPU 進行推論: 因為推論所耗的時間比訓練短,所以 GPU 與 CPU 的效能差異感受比較不明顯。如下圖案例,軟體內可以切換深度學習影像辨識要採用 GPU 或 CPU 來推論,相同的圖片,使用 GPU 平均耗用 11 ms 很快,但使用 CPU 平均耗用 95 ms,雖然差了 9 倍,但不到 100 ms 的計算時間對專案應用、機台設備的稼動時間來說未必會造成影響。所以您可以根據您的應用需求考慮使用沒有安裝 GPU 的電腦,單純用 CPU 來辨識節省硬體成本。
各種模型簡介
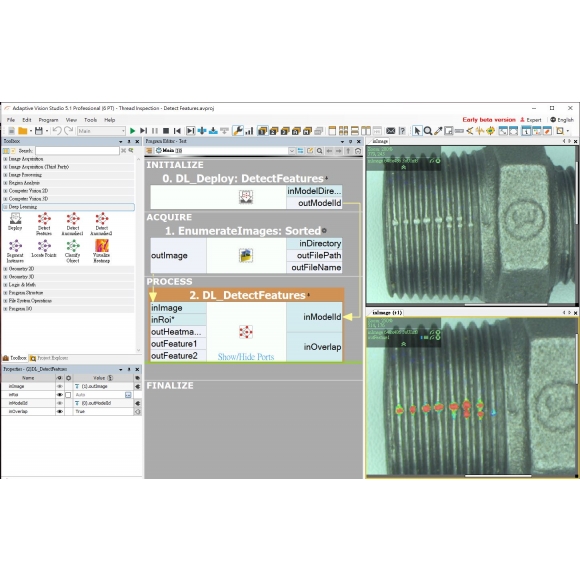
特徵檢測 (Feature Detection)
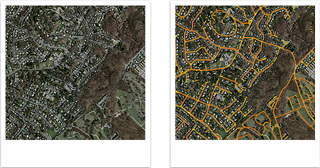
這是監督式學習的模型,也是最常用的模型,使用者需要小心地標註訓練集中影像,將缺陷、或您想辨識的特徵位置範圍畫上去。該模型會學習影像的 Key Feature 來判斷好與壞或您想辨識的特徵。太陽能板檢測

衛星影像識別
異常檢測 (Anomaly Detection)
這是非監督式模式,或嚴格來說是半監督模式的學習,只需要模糊的告知它良品或不良,使訓練過程更加簡單。適合用在沒有固定的缺陷定義,缺陷種類多樣化無法歸納的應用。這套模型需要提供良品圖樣,以及少量的缺陷圖樣供參考 (前後者比例大約 9:1 或更懸殊) 進行訓練,此後任何可疑的偏差都將幫您查找出來。包裝驗證
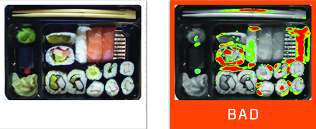
塑膠射出成型檢測

物件分類 (Object Classification)
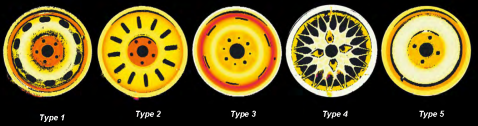
物件分類工具能將您輸入的影像,經過事先提供指定影像及指定分類來訓練,之後能自動區分影像類別,以及輸出類別名稱以及分類信心指數。瓶蓋:正面或反面

汽車 3D 鋁合金輪圈掃描檔案識別
個體區分 (Instance Segmentation)
個體區分技術被用來在一張影像中定位、區隔和分類單一或多重物件。它與 Feature Detection (特徵檢測) 不同的地方在於,特徵檢測模型可以找出物件的特徵範圍輪廓、特徵種類,但不能區隔同類型但不同個體的物件;而個體區分模型可以找出物件類型、物件的範圍輪廓,即使物件互相接觸或是重疊也能夠正確區分個體,雖然它的輪廓辨識精度比特徵檢測模型差。堅果分類

包裝驗證

特徵點定位 (Point Location)
如果您常涉獵深度學習新知,一定聽過 Object Detection 模型,這是一種經過訓練後,給定輸入影像,能輸出物體種類、包圍該物體的矩形方框 (bounding box) 的模型。特徵點定位模型是 Object Detection 針對工業應用的簡化版本,它不採用 bounding box 機制,您只要大略提供物體的中心位置以及搜尋半徑即可開始訓練,適合用來偵測具有一定程度形狀變化,但尺寸大小差異不大、個體為數眾多的工業應用案例。
蜜蜂跟隨

軟性物件的機器手臂取放

深度學習字元辨識 (Deep Learning OCR)
通常字元辨識 (OCR) 是機器視覺領域的一大挑戰難題,尤其是遇到不均勻的背景、字體模糊、反光材質時,用傳統方法做的 OCR 就不管用了,調整各種參數也很難提升辨識率。Aurora Vision 深度學習套件在 5.1 版以後提供用深度學習製作的 OCR 字元辨識功能,已經用上千種不同的影像訓練好一套模型,讓您可以不用訓練就直接掛載來使用,是辨識困難字型的解決方案。Aurora Vision Deep Learning Add-on 提供多種深度學習模型工具,以下是各種模型的用途示範。
深度學習並不是只能做瑕疵檢測 !! 即使是看似稀鬆平常的定位應用,您也可能有機會用到深度學習。
或許您原本認為只是用一般的影像處理工具就能做,但往往發現現實應用場景常常需要變更,於是在修改辨識演算法上疲於奔命。
我們若能善加利用深度學習,將原本完全用 rule-based 撰寫死規則死邏輯的判斷方式,改成用 sample-based 去學習的辨識方式,即使場景變了也不怕,學習一下就馬上能上線 !
操作示範
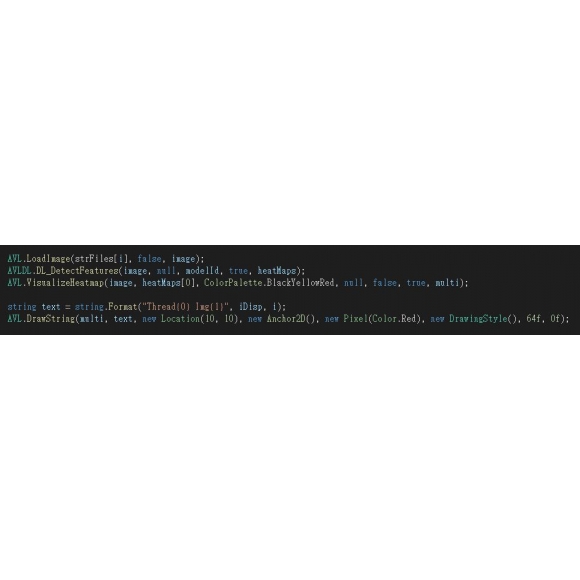
Aurora Vision 提供的 Deep Learning 解決方案,能在 Aurora Vision Studio、Aurora Vision Library 中呼叫使用,輕鬆完成取像、訓練、辨識、操作介面的一條龍設計。
甚至想要做 2D + 3D + AI 的互相整合,各取所長,也不用擔心。