
我們只討論與影像有關的
在帶出本篇主題之前,開宗明義先知會大家,本篇文章僅討論與影像有關的作法,如果各位看官還不清楚機器視覺影像辨識的軟體開發工程在做些什麼,請先跳轉【什麼是機器視覺軟體】。
先提示結果

我們先將影像辨識分為【傳統視覺】與【機器學習】兩種方案或者情境,這兩種情境不一定是非黑即白明確的分野,它們可能會有灰色重疊地帶。
上面這張圖表是一個經過歸納整理的結果,但不外乎,【傳統視覺】針對的是固定的東西、清晰的影像、良好的定義,以及非常明確的可靠度;【機器學習】針對的是軟性的東西、不穩定的影像、模糊的定義,以及帶有商量空間的可靠度。
先從傳統視覺開始講起
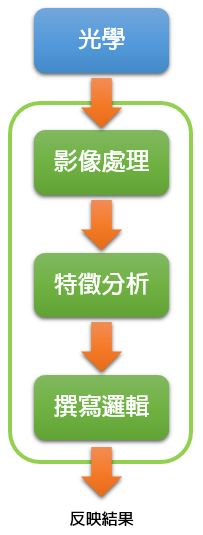
機器視覺發展許久,已經累積了經驗及套路,如左圖。
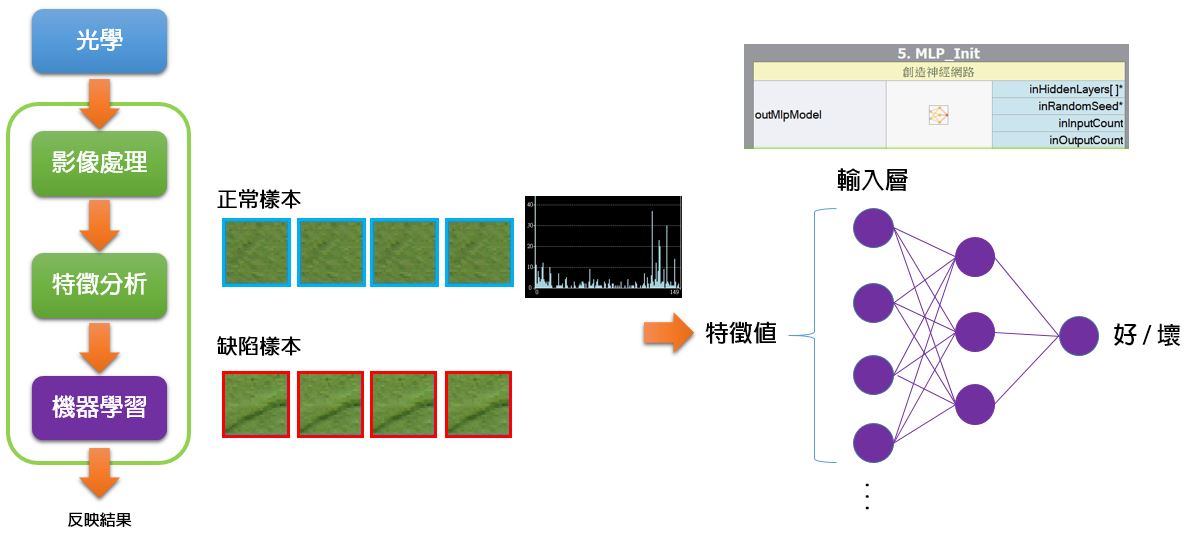
首先,你得先有一套光學取像系統,如藍色區塊,有好的打光,好的成像品質,以供給後續軟體分析計算一個穩定的資料來源。
至於打光及成像,可以參考【為什麼 AOI 光源有那麼多種形狀】【鏡頭 MTF 與相機選型的關係】等等文章。
接下來才是軟體工程師的事情,如綠色區塊,軟體工程師針對取進來的影像,撰寫影像處理演算法,分析影像特徵,最後寫一些判斷邏輯,如果是瑕疵檢測的案子,將會判斷影像是良品或不良品。
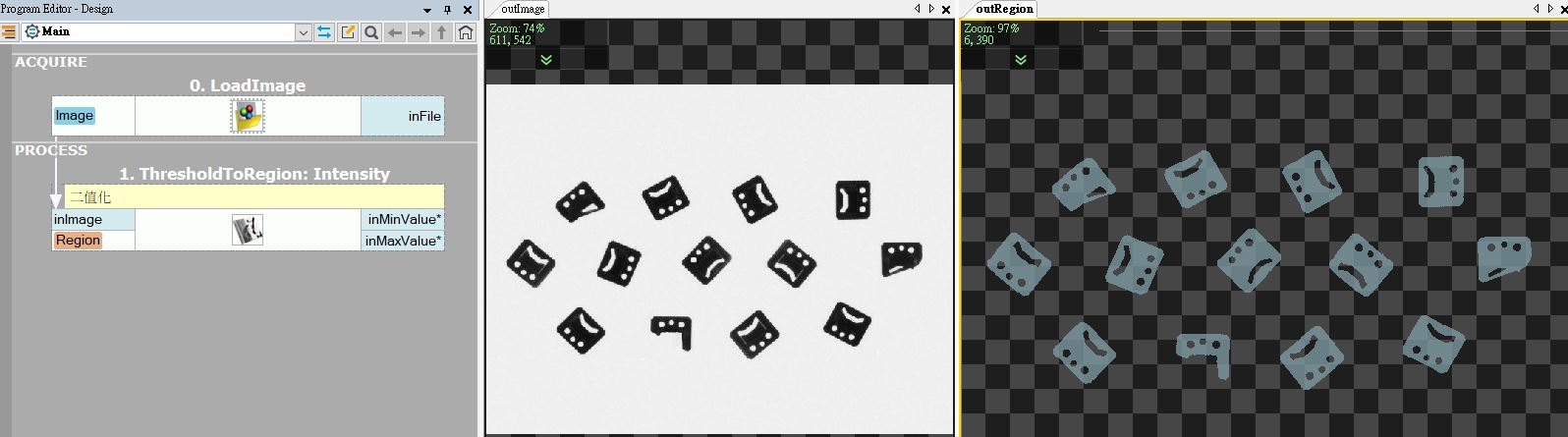
影像處理的招式很多,在學校初學【數位影像處理演算法】的同學,第一堂實作課程一定會練習【二值化】這個演算法,它是影像處理教科書的【Hello World !】,因為既簡單又實用。
我們就用二值化來介紹,二值化是一個相當簡單的演算法,你會寫一個迴圈遍覽整張影像所有的像素,給一個門檻值,把超過這個門檻的像素當作 ON,把低於這個門檻的像素當作 OFF;所以,當你的影像前景 (物件) 是某個灰階或顏色、背景 (非物件) 又是另外一個灰階或顏色,而且差異很大時,使用二值化技巧,可以很輕易的將前景與背景的像素分離開來,也就是經過二值化處理以後,前景都是 ON,背景都是 OFF。
【前景背景分離】在機器視覺中,是很重要的起手式,無論你是用哪一種演算法達成這個目的。
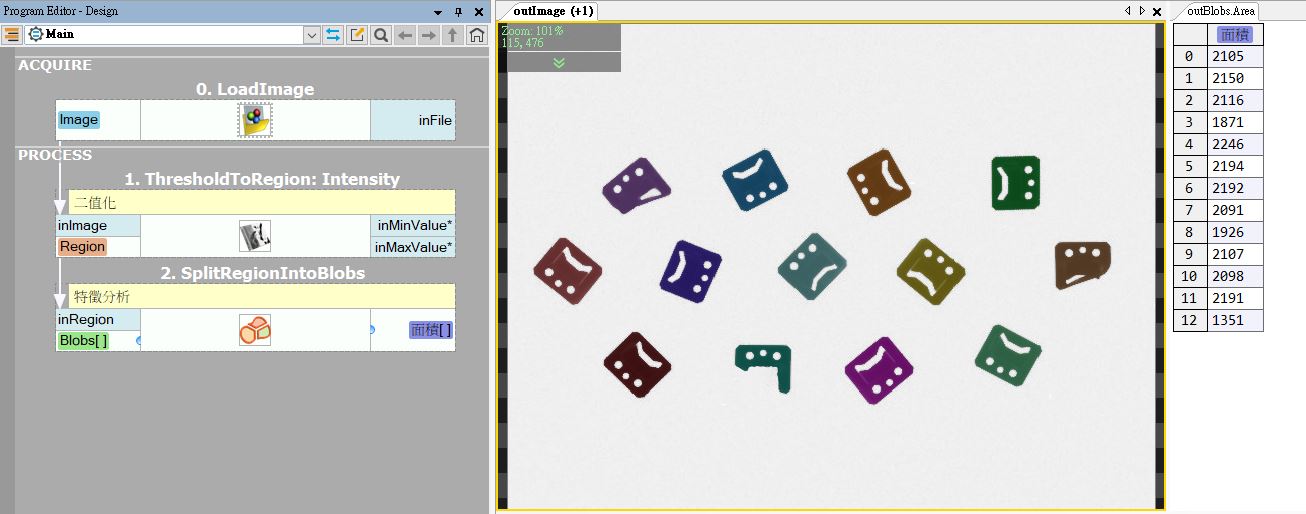
接下來,我們用【Blob 區塊分割】這個技巧,把 ON 的像素統計出來,把相鄰的 ON 算成一群,把不相鄰的 ON 算成不同群,之後就可以統計每一群的像素有幾個,得到像素的面積指數。
這個行為在機器視覺叫做【特徵分析】,所謂的特徵指的是有代表性的數字,例如上圖最右側的【面積】。

【特徵】來自於原始資料,由於我們的原始資料就是影像,影像是由眾多的畫素組成,畫素內是灰階值或是 RGB,即使它暗藏豐富的資訊,但你無法直接從畫素中馬上了解它的意義。
所以要【提取特徵】,例如上面這個案例,我們將數十萬、百萬、千萬的像素,降低資訊量,只剩十幾組面積值,有了面積值這樣簡單的資訊,我們才能做後續的邏輯判斷。
【特徵】就像我們的身高、體重、三圍、性別、膚色 ...
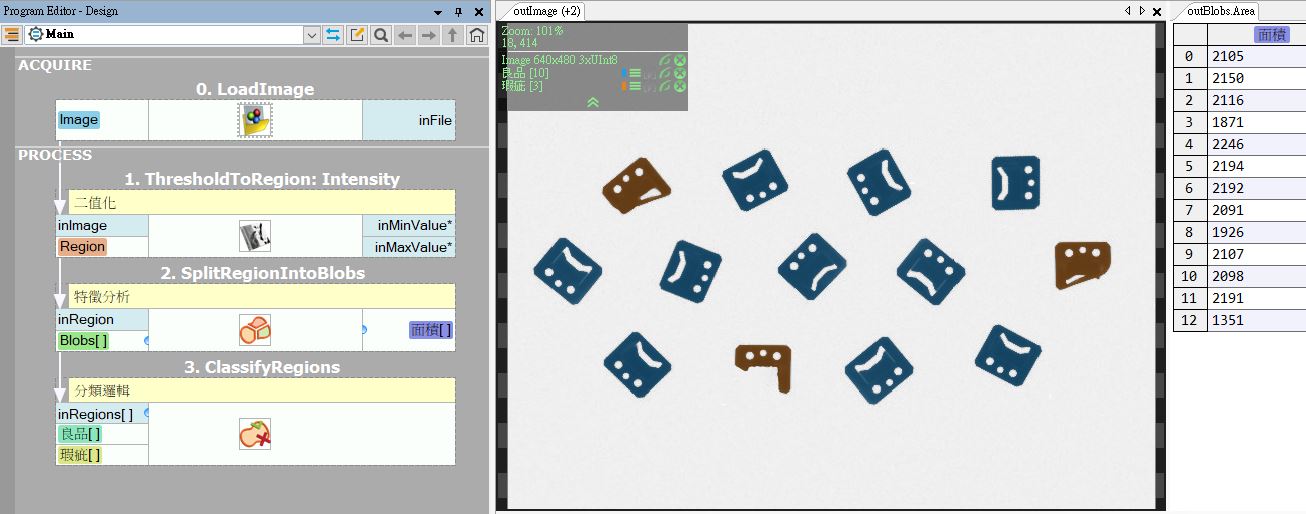
好的特徵必須具有鑑別力,我們認為,正常的良品必須要有一個規範內的面積尺寸上下限,過大過小的東西是不對的,所以,在這個案例中,【面積】這個特徵對於缺陷檢測的應用是有鑑別力的。
於是,一個經過優良打光,取得高對比影像,進行影像處理、特徵分析,最後撰寫邏輯判斷允收上下限,來製作的自動化光學檢測系統就這麼做出來了。
再多舉幾個案例。

在量測或者計數的案例中,我們很常用影像處理技巧抓取影像的【邊緣】,所謂的邊緣指的是由淺色到深色、或由深色到淺色,劇烈變化的地方。
能夠穩定抓取影像的邊緣,利用邊緣來定位前景,才能進一步【特徵量測】這個邊到那個邊的【距離】。

邊緣還有更多的用法,例如在形狀檢測的案例中,我們先做【對位】之後,再【比對】物件的外框與標準物件的外框是否吻合,將不同之處提取出來。
講到這裡,各位應該約莫可以勾勒出傳統機器視覺的解決方案,會有這些條件限制,
- 影像對比度很重要。前景背景最好是非黑即白就能區分,如若不然,就用循邊技巧去區分。
- 物件的形狀最好是固定的。固定的形狀才能去做量測、對位,或者形狀比對。
如果超出這個限制怎麼辦?

這是一個表面紋理 (Texture) 檢測的案例,所謂表面紋理檢測,通常要在富有花紋的背景中,檢測出破損、刮傷等等外觀上的缺陷。
這些外觀缺陷【沒有固定形狀】,如上圖,我們若將大張影像提取一個一個小圖塊出來,你頂多發現這些圖塊似乎透著某種規律,但很難具體描述它是什麼形狀。

因為標的物本身帶有豐富的花紋,很難用單純的二值化、邊緣提取等等技巧去區分正常的花紋還是異常的花紋。
主要原因在於,進行影像處理後,這些花紋依然很難用簡單的規則所量化。
其實特徵還是有跡可循的

剛才提到,當你看著這張影像出神,發現這些缺陷的圖塊【似乎透著某種規律】。既然好像有什麼規律,那我們必須要想辦法去量化它。
其實,還真有許多技巧可以約略的量化這些規律。
例如上圖右,這是一種叫做 Histogram (直方圖) 的特徵,它統計圖塊中的所有像素的灰階值。
用直方圖表示時,橫軸代表不同的灰階值,縱軸代表屬於該灰階值總共有多少個像素。
這種統計特徵不像前面提到的【面積】【距離】... 等等這麼直觀,就像分析股市會有什麼指數什麼指數那樣,但它就是可以量化目前的情況。
無論你用的是 Histogram 還是用其他的演算法,你的思維是【想辦法將該影像轉換成一組獨特的身分 ID】,這樣接下來就有辦法去作分析了。
但還是有問題,由於這種特殊的特徵指數實在很不直觀,就算好像看得出什麼規律,但我們不太容易直接寫個什麼判斷式,例如【大於多少就怎樣,小於多少就怎樣】去分析這類特徵。
很難寫簡單的邏輯去歸納這種特徵,那就用樣本去決定吧
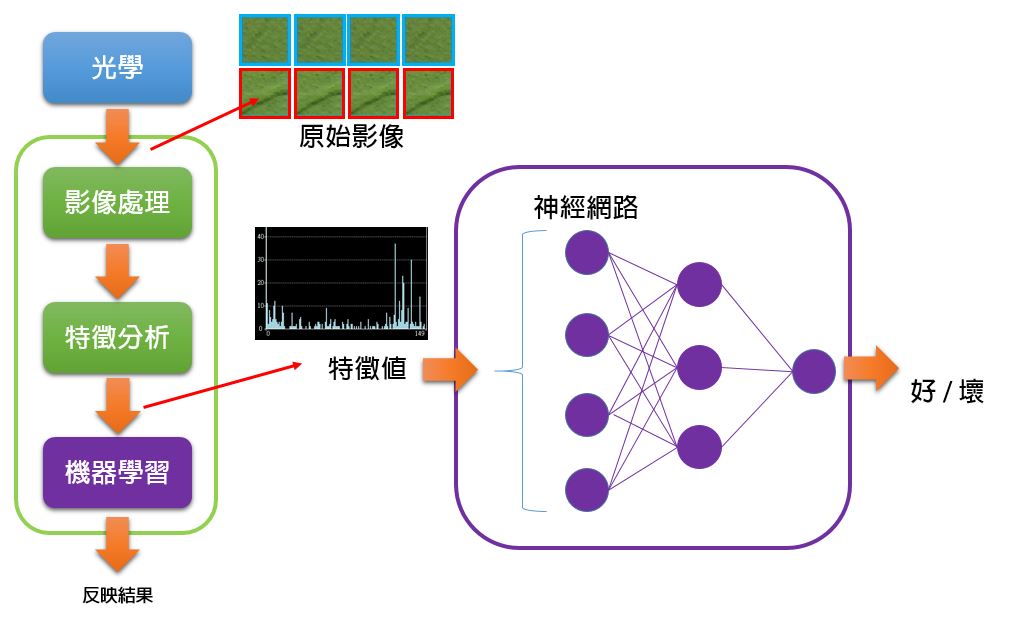
由於這些特殊的特徵指數實在很不直觀,就算好像看得出什麼規律,但我們不太容易直接寫個什麼判斷式,例如【大於多少就怎樣,小於多少就怎樣】去分析這類特徵。
這時候,就是進入機器學習的範疇了。
於是,我們可以挑選某種機器學習演算法,例如【神經網路】,將眾多的樣本圖塊產生出來的特徵數值丟進去,並且給它已知的答案。
經過一連串的訓練結束後,讓機器學習模型只要輸入某組特徵指數,它就會自動反應出它是良品還是不良品的結果,代替我們去歸納那些特徵指數。
機器學習的演算法眾多,有的適合做迴歸分析,有的適合做分類,有的適合做分群,端看你想要分析的資料類型、特徵類型是什麼。
然而,每一套理論要能熟練駕馭它,都必須對它充分的了解,所以研究機器學習通常是專門領域的工程師或科學家。
不過在這裡,我們只要知道一件事,機器學習可以【提供樣本資料,經過訓練以後,讓電腦能夠自己判斷】。
注意,我們甚少直接用原始像素值去訓練機器學習。
從剛才的套路可以看到,我們是先做影像處理,再來分析特徵指數,最後才叫機器學習來做最後的決策判斷,也就是【壓垮駱駝的最後一根稻草】。

影像處理的演算法眾多,特徵擷取分析的演算法眾多,機器學習的演算法眾多,在在都需要專業領域的工程師去挑選適合的技巧去對付適合的案子或應用。
在早年,光是研發一種獨特又有效率的特徵擷取演算法,就可以發表一篇重大學術論文了。
(上圖: 2001 年 Viola-Jones 發表利用統計小圖塊的上下、左右、對角線等等的灰階差當作初級特徵值,利用這些特徵值進行下一步的訓練,用於快速辨識照片中是否是人臉。)
例如我們剛才用 Histogram 去統計影像特徵,可能在這個案子中是有鑑別力的,但換個案子、換個不同類型的影像,或許就不適用。
有辦法直接學習原始影像嗎? . . . 深度學習橫空出世
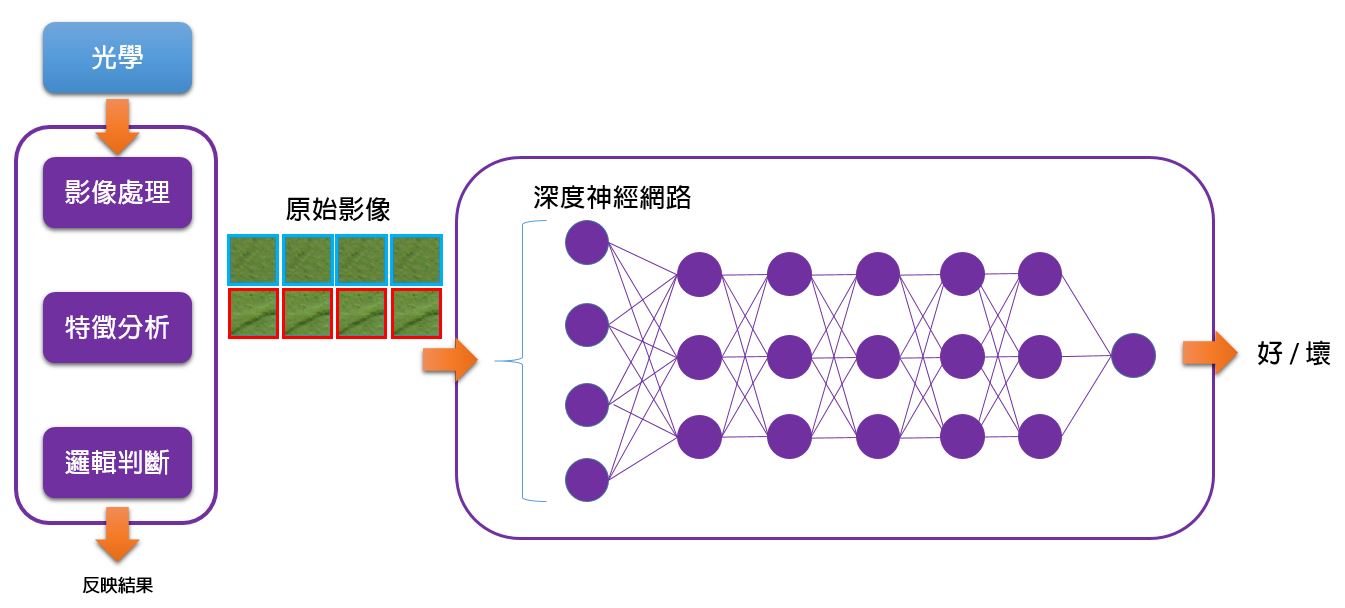
為什麼不能直接讓機器學習直接分析原始影像 ?
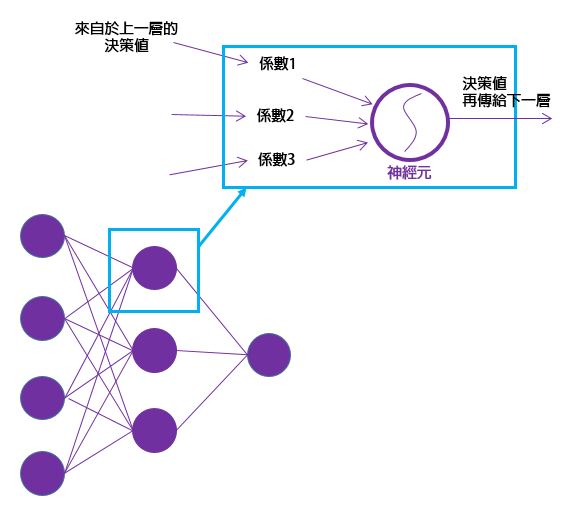
神經網路發展幾十年的歷史了,我們把神經元單獨拉出來看,它的輸入端連接著網路的前一層的神經元的輸出,並且每一條神經線都乘上一個係數 (權重值: 表示重不重視的強度),彙總起來到神經元身上後,給定一個閥值,決定輸出值為多少,再把這個數值傳給下一層。訓練的時候其實就是透過某個數學規則去調整這些權重係數,若上一層提供的某項訊息對整體結果有正向幫助,則訓練時會再一次提昇該權重,反之則抑制該權重,最終使得讓整體結果為最好。
每一個神經元都不直接參與最終的決策結果,而是大家共同分擔。
曾經有這麼一種說法,只要神經元夠多,沒有不能解決的問題。
於是把神經網路做得非常龐大,超級多的神經元,堆疊得很深很長,故稱深度神經網路 (Deep Neural Networks),簡稱 DNN,訓練這種神經網路的技術就叫做深度學習。
卷積神經網路
當我們癡心妄想想要將一堆神經元串接整張原始影像,發現資料量實在太大了,導致訓練過程難有成效。
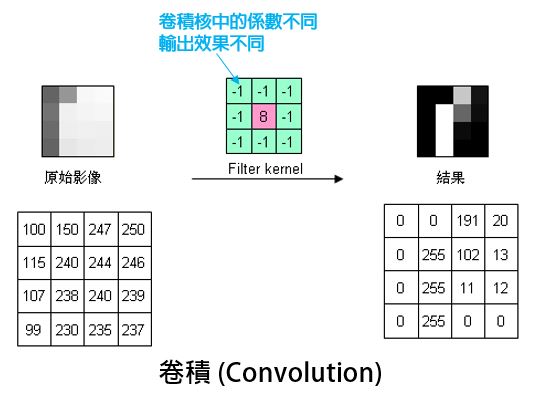
科學家們發現,我們平常在用的基礎影像處理演算法卷積 (Convolution) 是可用之材。
卷積運算需要一個 Kernal,叫作卷積核,卷積核是一個矩陣,每一格內都有一個係數,不同的係數的卷積核對影像會有不同的處理效果。
例如上圖,這個卷積核對影像有邊緣強化的效果;有的卷積核對影像則是模糊化的效果。
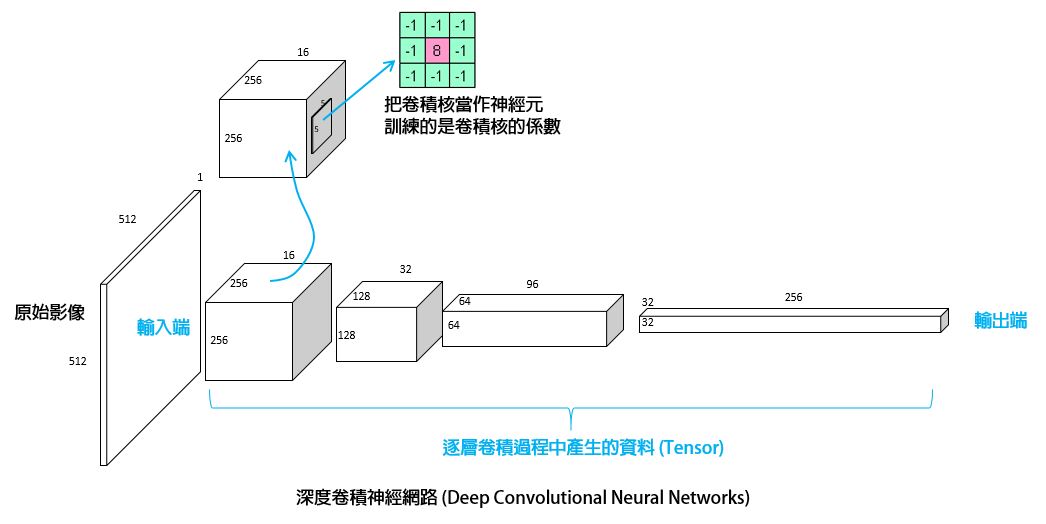
於是,用卷積核當作神經元,將輸入影像一邊作卷積、一邊降低維度 (解析度 / 畫素)、逐層抽取特徵資訊,最後作出決策的網路,就叫做卷積神經網路。
該網路訓練的是卷積核的係數,到底什麼樣的係數可以卷積出我們要的結果那不重要,把它當作一個黑箱子,反正經過訓練後最終的結論是對的,就這麼辦。
卷積神經網路的輸入、輸出,以及中間傳遞的資料,資料的尺寸用 Width x Height x Depth 表示。例如一般我們常見的影像通常是 Width x Height x 1 (灰階) 或 Width x Height x 3 (彩色)。
我們用 Tensor (張量) 這個名詞表示這種廣義的影像資料,鼎鼎大名的 Google Tensorflow 深度學習框架用的就是這個單字。
不同的卷積網路功能不同
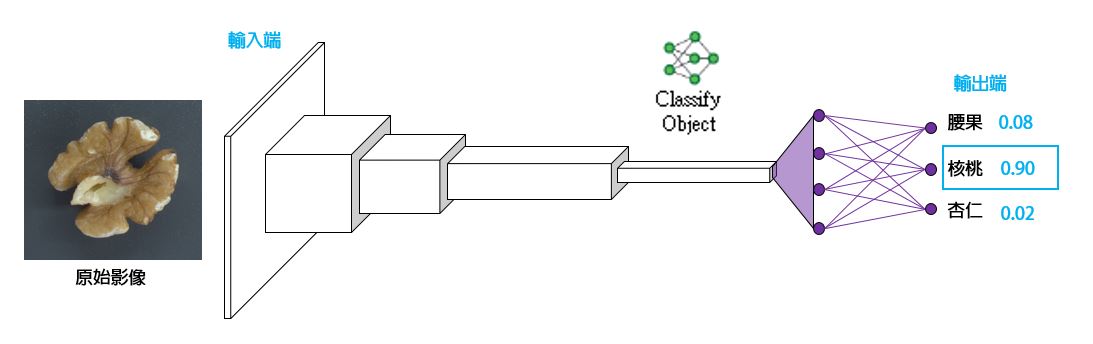
由於卷積網路傳遞的是 Tensor,輸出也是 Tensor,還沒有彙整成為單一的決策數值,所以,我們把卷積神經網路的末端,接上一般的神經網路,可以做到決策判斷輸出。
如上圖,若末端第一個神經元數值最高,則辨識結果是腰果,若第二個最高,則辨識結果是核桃,依此類推。
這種網路泛稱為 Classification 模型,用來輸入一整張圖片,然後分類整張圖片是什麼東西。
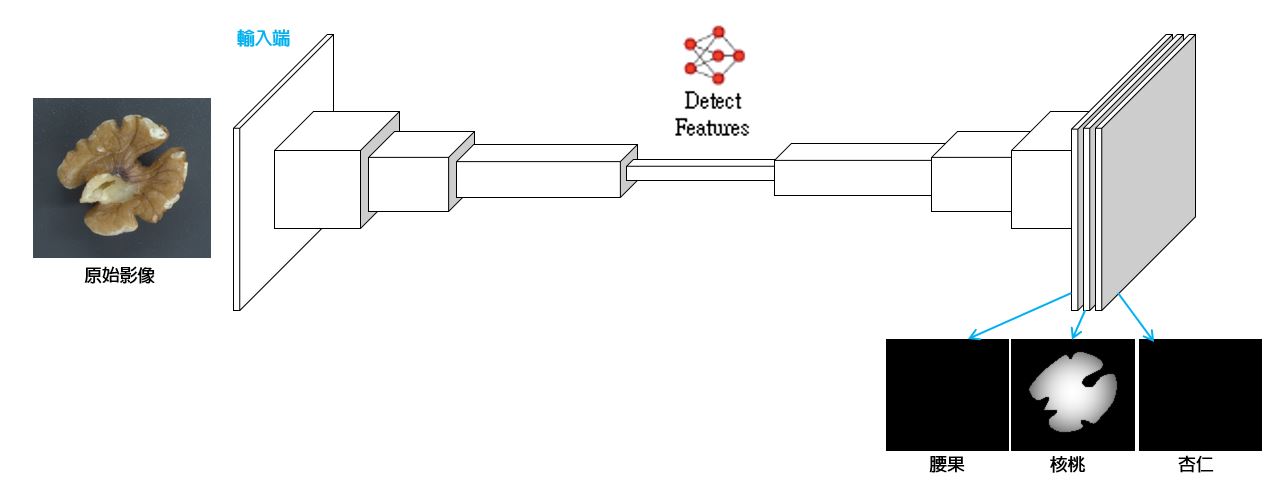
如果我們想知道這張影像哪個像素屬於核桃的一部分,哪個像素不是呢?
我們可以用卷積網路,將它的輸出變成好幾層不同的 Heatmap (一種 Mask,數值高的像素表示該位置很可能屬於這個類)
這種網路泛稱為 Segmentation 模型,用來輸入一整張圖片,然後給出把指定類別的物件當作前景切割出來的 Mask。
在 AOI 的應用中,常這種模型去訓練辨識瑕疵的具體位置、或者其他一些想要標定出來的影像特徵。
各種深度學習模型的用法
回顧結果
我們從傳統影像處理演算法,講到傳統機器學習,再談到近年最火熱的深度學習技術。
再回顧一下之前的結論:
因為前者能處理的案件有條件限制,軟的不能做、反光的不好做、紋路的很難處理,所以只好透過樣本去訓練,解決了各種限制問題。因為是靠樣本去決定的,明確的樣本導致明確的結果,混淆不清的樣本導致模稜兩可的結果。俗話說 Garbage In Garbage Out,樣本的篩選、訓練標註手法的好壞、有沒有一致都會影響結果,機器學習的可靠度永遠不可能是 100%,所以估個 99% 吧,能夠解決本來不能處理的問題也相當的了不起。
後話: 沒有明確的分界線

這是一個【指針讀碼器】的應用,利用相機拍攝表頭上的指針,辨識出指針角度後反推指針的讀數,將讀數數位化。應用於 IOT (物聯網,Internet of Things),因為許多傳統機械本身因為沒有設計Sensor 以讀取數位資料、上傳數位資料的能力,加裝上 IOT 裝置能升級它們的功能,但不去破壞它本身的既有設計。
各位看官可以觀察,影像對比度高、物件形狀是固定的,您會選擇用傳統影像處理來做,還是機器學習?
沒有標準答案。